
最近开始上斯坦福大学cs231n的公开课。其实上学期已经过了一遍cs224d了,当时看的是无字幕的视频,感觉收获并不是特别大,可能是由于学习的时候断断续续很多实现的细节还是没有理解。这次学习cs231n就只是看了课程网站上的lecture note,跟着写了写作业。cs231n的内容涉及到机器学习中的多种算法以及 cnn/rnn等多种神经网络,之后的作业也还都比较有趣。现在写了第一周的作业,主要涉及到了几种分类算法,在这里小结一下。
knn算法
一般来说,knn作为无监督学习(unsupervised learning)可以作聚类,这里把knn作为监督学习(supervised learning),将CIFAR-10 dataset中的图片作为训练集和测试集,将测试集中的每一张图片与训练集中的每一张比对,选出最相似的k张,这k个label中出现次数最多的就是测试集的判定分类结果。
L1与L2距离
为了计算两张图片之间的差距,把数据集中的32 32 3的原始图片延展成一个一维向量,共有32 32 3维特征。
对于测试集与训练集的距离计算,有两种方式,L1距离与L2距离。
L1距离:
L2距离:
基于L1距离的knn分类算法在CIFAR-10上的准确率可以达到38.6%,而基于L2距离的knn分类器准确率则为35.4%。对于L2距离而言,由于距离之间的差有平方,L2在距离差异较大时会产生更大的分歧。
knn分类的优缺点
- knn的优点在于,算法非常简单直观,不需要额外的训练时间。
- 缺点在于虽然缺少了训练过程,但是分类的测试时间非常长。且在每次做分类过程中都要与所有的训练数据比较,空间复杂度也很大。在图像分类中,由于维度特别高所以knn也使用不多。
线性分类器
为了解决knn算法中出现的时间和空间开销太大的问题,这里提出了线性分类器。线性分类器分为两个部分,首先是一个得分函数将输入的原始数据映射到每一个分类label的得分,第二部分是一个可以量化预测得分和真实分类的损失函数。
利用线性分类器进行分类的具体步骤如下:
- 首先进行数据的预处理,一般来说在机器学习中输入特征总是会被归一化(在图像的情况下,每个像素就是一个特征)。具体来说每个像素都要减去所有像素的平均值,之后再缩放这些特征,使得所有特征的取值范围都在[-1,1]。
- 在进行
计算时,可以将x向量增加一维并全置1,相应的把对应的权重矩阵W也增加一维,这样原本的W,b两个参数就可以变为一个参数。
- 在通过得分函数计算出了每个变量分在每一个类的得分之后,得分最高的就应该是预测的分类结果。
上面提到的是测试分类的过程,训练的过程就是通过大量的训练数据集不断调整W与b,使得其能有最好的分类结果。而W和b的调整标准就在于loss function,loss function在预测结果与真实结果最为接近时值最小,通过最优化算法(梯度下降,牛顿法/拟牛顿法)通过每次迭代loss function的函数值来更新W,b的值,使得在训练结束之后得到的W和b能较好反映图像的特征。下面提到的SVM与Softmax实质上就是两个不同的loss function。
SVM loss
这里的SVM与cs229等其他机器学习中提到的复杂SVM算法有一定区别,它采用SVM核心的hinge loss,没有讨论svm中涉及到的kernel,dual以及SMO算法。 SVM loss 希望每个图像正确分类的得分比不正确分类的得分高得至少一个固定Δ。
具体来说,对于第i个例子,我们给出了图像的特征(即像素)与正确分类的标签。得分函数利用输入的像素计算的分类得分。第i个训练数据多分类SVM的损失可以表示为:
从下图也可以看出,svm的loss希望分类正确的得分比分类错误的得分至少高Δ,如果没有做到,那么损失将会累积。")
这里的Δ的取值一般为1,其实Δ的变化可能就是使W与b成倍放大和缩小,而不会对分类结果有很大影响。
Softmax loss
softmax分类器是逻辑回归分类的一般情况。与SVM的loss相比,softmax将对分类得分有一个更直观的概率解释。得分函数不变,但是我们会用log概率处理这些得分并把svm中的hinge loss变为cross-entropy loss(交叉熵损失):
Softmax函数的一般形式为, 它的输入为任意的实数向量,输出和输入相同维度向量,其中每一个数都在0与1之间且相加的和为1.从上式可以看出,当分类正确的得分越大,分类错误的得分越小,损失就越接近于0。这里借助了概率论中交叉熵的思想。
在实现softmax算法时,为了计算的稳定性,通常令输入的实数向量中每个值都减去该向量中的最大值,因为:
分析与比较
- Softmax loss function的输出可以看作是分类的概率,而SVM的输出结果没有含义,但是softmax得到的分类概率与正则化参数λ有关。(后面将会提到正则化)
- 与Softmax相比,SVM有”局部目的性”(local objective)。 对SVM而言,只要正确结果的得分比错误结果大Δ,那么loss将会为0.如 [10, -100, -100] 与 [10, 9, 9]两个得分(第一个为正确分类结果),SVM产生的loss是一样的,而Softmax则永远不会对分类结果“感到满意”,即Loss永远不会为0。它希望分类正确的得分越大越好,分类错误的得分越小越好。这样的特性也使SVM与Softmax分别有不同的应用领域。
神经网络
神经网络模型
神经网络是由很多神经元结合在一起,一个神经元把很多的输入x1,x2,x3… 以及截距+1(偏置)作为输入.与SVM和softmax相似的,这里也有一个得分函数将输入映射到一个得分,z = Wx+b。之后再用一个激活函数f将得分z作一个非线性的变换,然后输出。这里的非线性函数有很多种选择,tanh,sigmoid,reLu都是常见的激活函数。
神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。例如,下图就是一个简单的神经网络: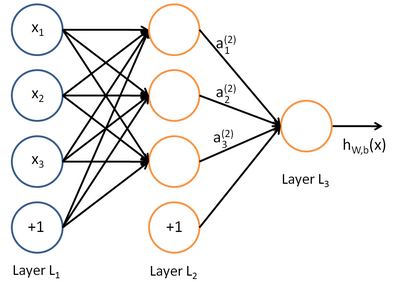
我们使用圆圈来表示神经网络的输入,标上“ +1”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层(本例中,输出层只有一个节点)。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及一个输出单元。
一般我们用用来表示网络的层数,
表示第 l 层第 i 单元的激活值(输出值),我们用
表示第 l层第 i 单元输入加权和(包括偏置单元),f
表示激活函数。整个神经网络可以表示为:
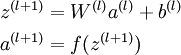
求解这个网络,即是通过大量已经标记号的数据(x,y),获取最合适的权重矩阵W与b,使得能得到最好的分类结果。下面提到的反向传播算法就是神经网络的训练算法。
反向传播算法
反向传播(Backpropagation)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法计算对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
反向传播要求有对每个输入值想得到的已知输出,来计算损失函数梯度。因此,它通常被认为是一种监督式学习方法,虽然它也用在一些无监督网络(如自动编码器)中。它是多层前馈网络的Delta规则的推广,可以用链式法则对每层迭代计算梯度。反向传播要求人工神经元(或“节点”)的激励函数可微。
由于神经网络的loss function不是一个凸函数,所以有可能会收敛到局部最优解,但是通常情况下反向传播的结果都不错。另外,在进行反向传播算法前要将参数进行随机初始化,而不是全部置为0。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数随机初始化的目的是使对称失效。
反向传播算法可表示为以下几个步骤:
- 进行前馈传导计算,利用前向传导公式,得到
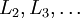 直到输出层
直到输出层 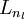 的激活值。
的激活值。 - 对输出层(第
层),计算:
- 对于
, 2 的各层,计算:
- 计算最终需要的偏导数值:
}} J(W,b;x,y) &= \delta^{(l+1)} (a^{(l)})^T")
分类中的其他问题
正则化
引入正则化的原因在于,我们想要得到的权重矩阵W是不唯一的。如果W变为原来的2倍得到的分类效果理论上是一样的,但是相应的Loss却相差两倍。我们想要在Loss function上加上一项来移除对于W的模糊性,这一项称为正则惩罚 R(W). 最普遍的L2正则惩罚是权重矩阵W中所有项的平方和:
修改后的Loss function变为:
除了L2正则项,还有L1正则项,但L2正则项更倾向于所有的权重变得更加分散,即最后的得分是所有特征综合的结果。正则化参数λ可以通过验证集选取。
最优化算法
在我们构造出了相应的score function和loss function之后,下一步就希望能通过在训练集中评估loss function得到的预测结果和真实结果的差来更新score function中W和b值。 最优化算法就是根据每次得到的预测loss来对W和b中元素值进行调整,从而使模型有更好的分类结果的过程。
最优化中最经常使用的是梯度下降法,其核心思想就是用微积分或数值分析的知识计算出loss function关于W和b的梯度,然后逐渐让W和b沿着求出的梯度方向下降,直到最后loss趋向于一个稳定值。
梯度下降法在很多实例中可以取得不错的结果,但是它要求loss function是一个凸函数,否则可能会收敛到局部最优解。梯度下降法有如下几个要点:
- 由于每次都把所有的数据计算一次loss计算开销太大了,所以经常采用随机梯度计算的方法,把数据分成很多batch,每次只是计算每个batch的loss。
- α的值可以通过验证集确定
- 无法用微积分直接计算梯度时,可以用数值计算的方法
得到梯度。
validation sets
对于knn算法中的k,线性分类器中的正则项系数λ以及学习速率α,这些参数都对最后的训练结果有极大的影响。我们在确定了分类模型之后,需要找到最好的超参数(Hyperparameter)从而在测试集中得到最高的准确率。
之所以不能用测试集(test set)来获取超参数,有两个原因。当我们使用原本的测试集我们可能对于某一些超参数可以获得很好的分类准确率,但是当我们的模型被应用到其他的数据时结果也许就不佳。这种情况就说明测试集过拟合了。还有一个原因是,如果用测试集来训练的到超参数,其实也就把测试集当做了训练集,所以在测试集上得到的结果并不能很准确的反映模型的好坏,所以这里我们引进了验证数据集(Validation sets)。一般来说,我们把所有标记过的数据分为测试集,训练集,验证集三个部分,三个部分的比例为7:2:1.
特征提取
对于线性分类器而言,如果把RGB原图压缩成一个一维向量,那么输入的维度就太大了。所以在做图像分类之前,一般都要先提取特征。 特征提取是图象处理中的一个初级运算,它检查每个像素来确定该像素是否代表一个特征。假如它是一个更大的算法的一部分,那么这个算法一般只检查图像的特征区域。作为特征提取的一个前提运算,输入图像一般通过高斯模糊核在尺度空间中被平滑。图像特征一般分为颜色特征和纹理特征。
在cs231n的作业中,对输入的CIFAR-10图片提取了hog特征,方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。

